The alignment of representations from different modalities has recently been shown to provide insights on the structural similarities and downstream capabilities of different encoders across diverse data types. While significant progress has been made in aligning images with text, the temporal nature of video data remains largely unexplored in this context. In this work, we conduct the first comprehensive study of video-text representation alignment, probing the capabilities of modern video and language encoders. Our findings reveal several key insights. First, we demonstrate that cross-modal alignment highly depends on the richness of both visual (static images vs. multi-frame videos) and text (single caption vs. a collection) data provided at test time, especially when using state-of-the-art video encoders. We propose parametric test-time scaling laws that capture this behavior and show remarkable predictive power against empirical observations. Secondly, we investigate the correlation between semantic alignment and performance on both semantic and non-semantic downstream tasks, providing initial evidence that strong alignment against text encoders may be linked to general-purpose video representation and understanding. Finally, we correlate temporal reasoning with cross-modal alignment providing a challenging test-bed for vision and language models. Overall, our work introduces video-text alignment as an informative zero-shot way to probe the representation power of different encoders for spatio-temporal data.
As models are trained on larger datasets with similar architectures, are they learning similar representations of the world? This idea was posited in [1] as the Platonic Representation Hypothesis, suggesting that even if one model is trained on images and another on text, they may learn to organize their "understanding" of the world in a similar way. More formally,
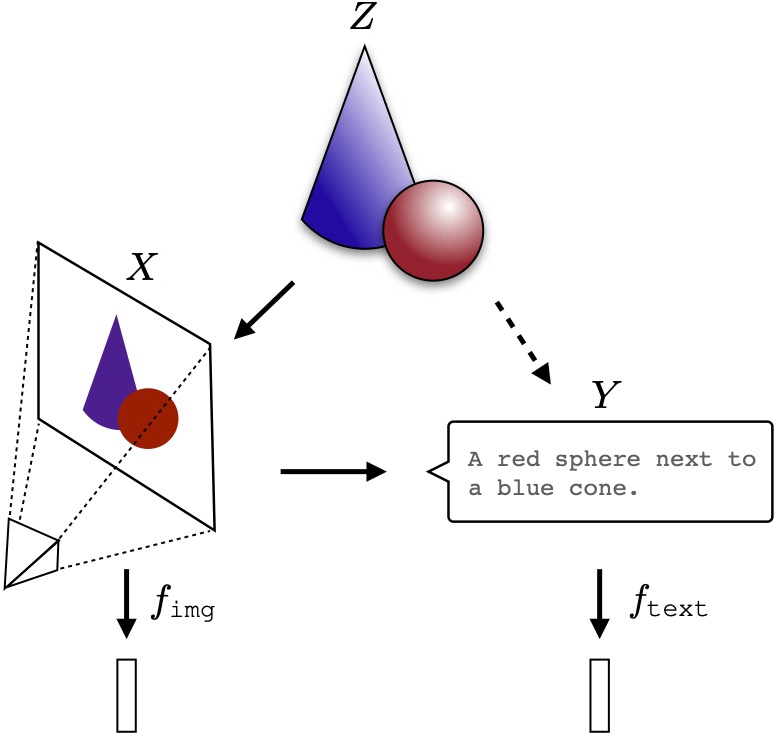
Neural networks, trained with different objectives on different data and modalities, are converging to a shared statistical model of reality in their representation spaces. - Huh et al. 2024.
This, of course, is a reference to Plato's Allegory of the Cave [2]. Fundamentally, all data is a projection of a shared reality - text, images, videos, audio, etc. As we observe more of it, we converge closer to the source of truth where they came from.
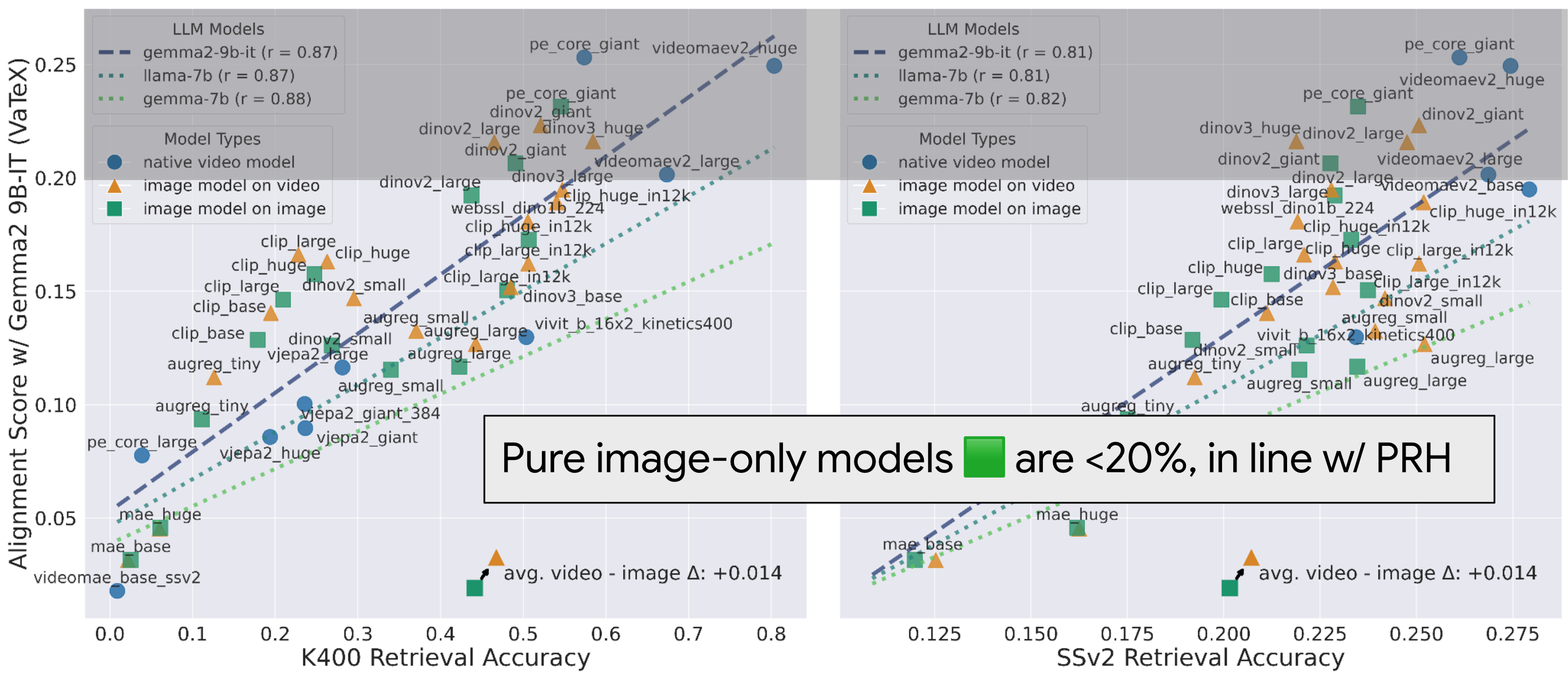
Modern image models and LLMs were evaluated for their alignment on static data like images and text, with the best performing models scoring an alignment close to 0.16 [1]. This prompted the authors to wonder, "Is a score of 0.16 indicative of strong alignment [...] or does it signify poor alignment with major differences left to explain? We leave this as an open question."
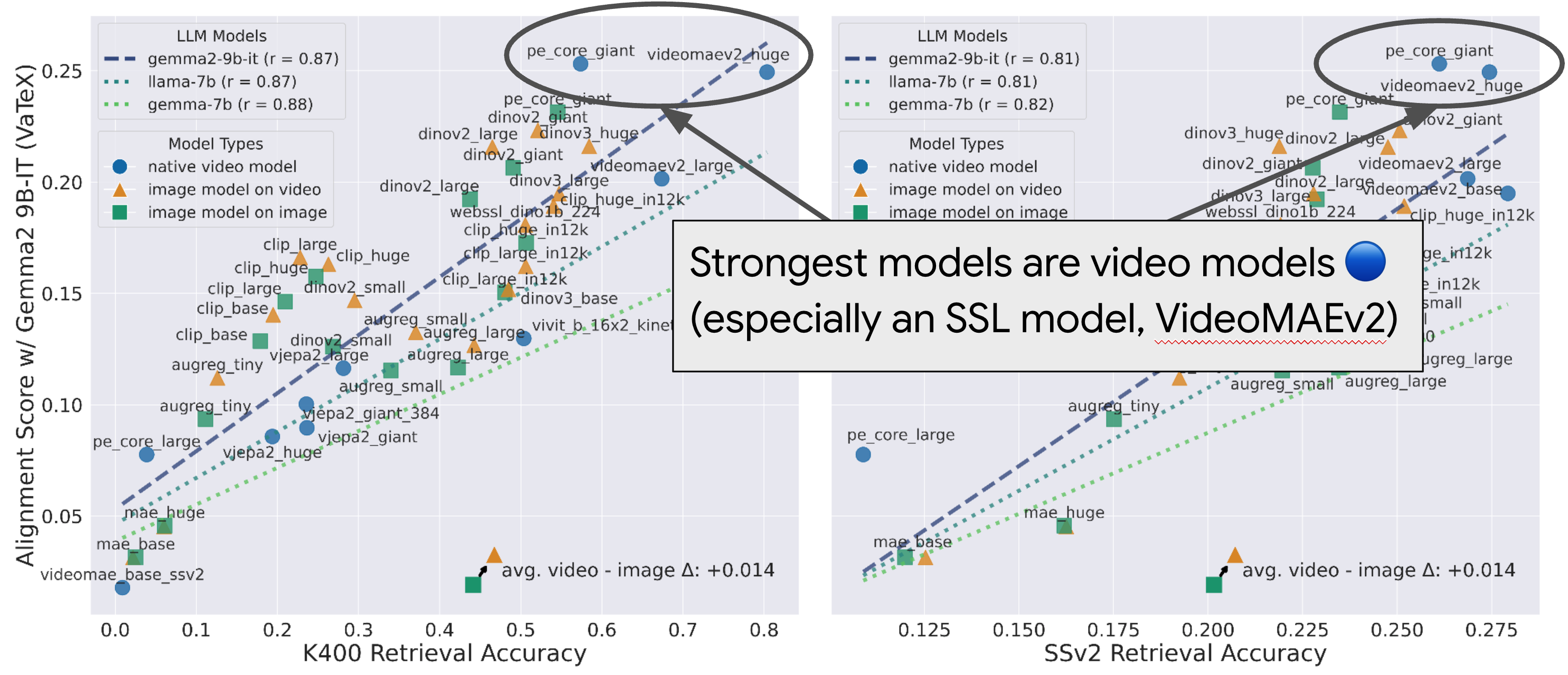
Our work addresses this resoundingly, showing that alignment for the exact same models can almost double by considering dynamic inputs, and achieve nearly 0.40 for video models, which more accurately reflect the true underlying representation from the real world. Strong alignment was in these models all along; the data was just too impoverished to reveal it!
To quantify how "similar" two representation spaces are, we need a metric that can compare their geometric structures without requiring them to be in the same coordinate system. We use a method called Mutual $k$-Nearest Neighbors (k-NN) Alignment. The intuition is simple: if two spaces are well-aligned, then points that are close to each other in one space should also be close to each other in the other space.
While the spaces need not be in the same coordinate system, we need a dataset of paired video and text captions to link the two modalities together. We utilize two datasets of 1024 pairs: the VaTeX dataset, consisting of 10-second YouTube clips captioned by 10 different English annotators, and the Perception Encoder Video Dataset (PVD) ([3], [4]).
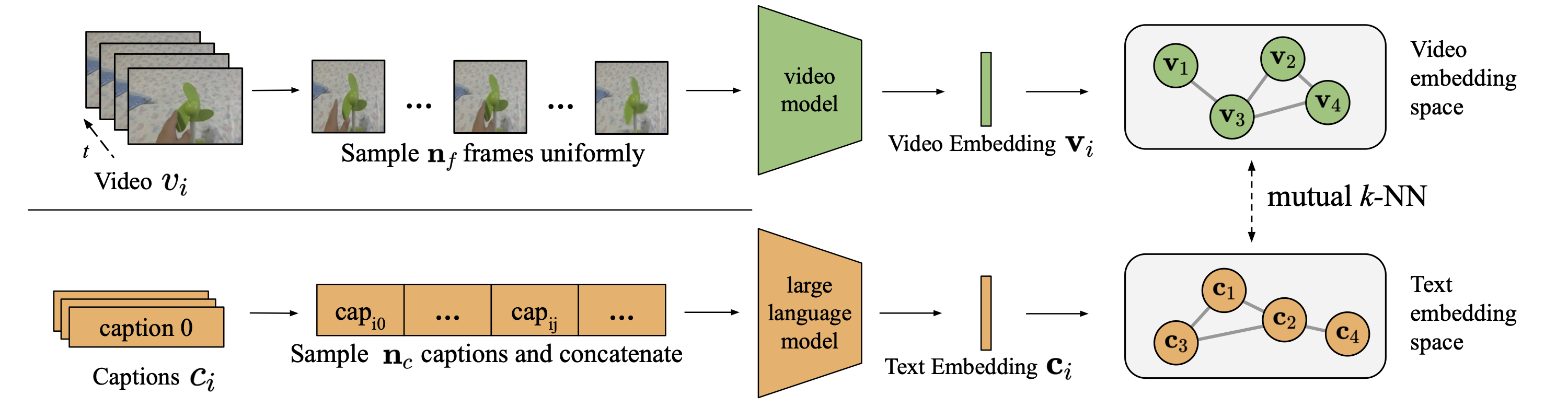
Here's how it works for a dataset of paired videos and text captions:
A higher score means the neighborhood structures are more consistent across the two modalities, indicating stronger alignment. This metric is powerful because it's "zero-shot"—it requires no training or fine-tuning to compare the models.
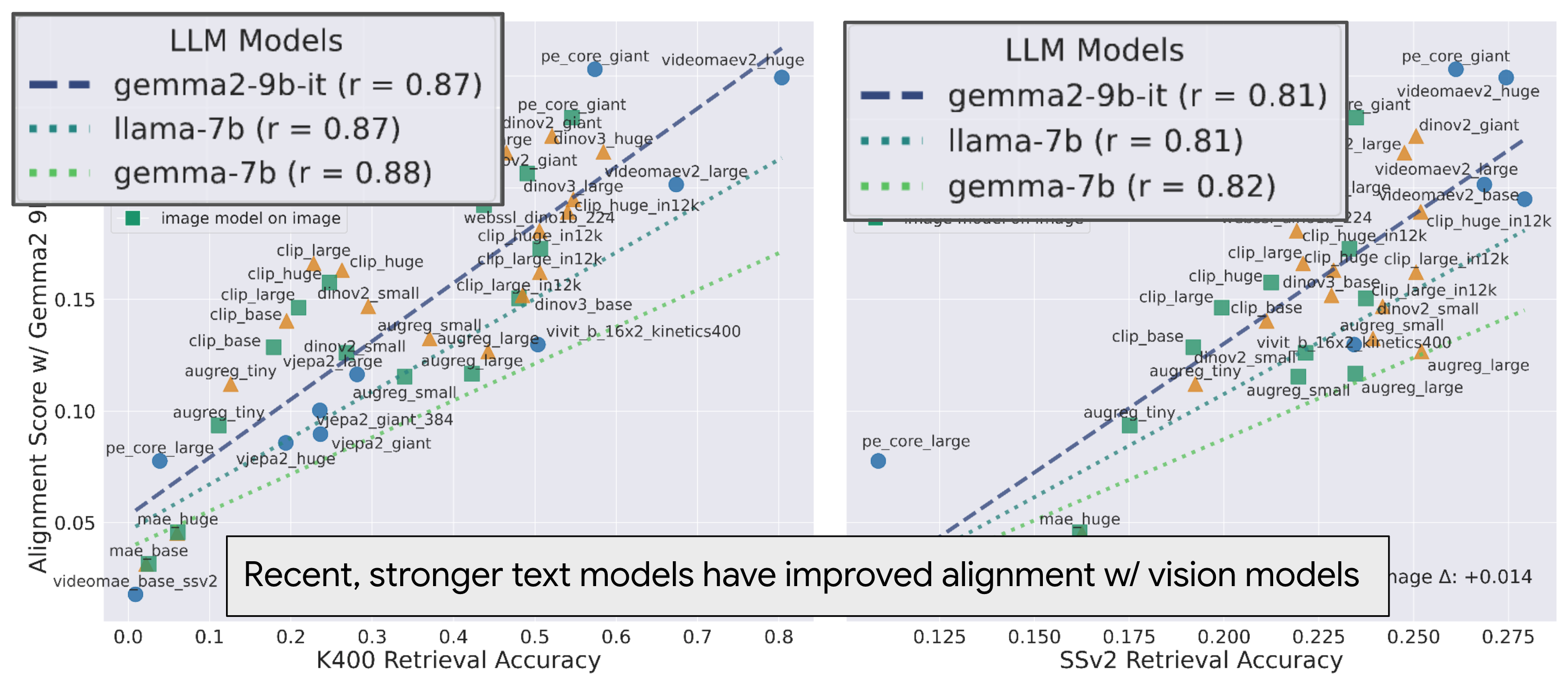
We first measure alignment of various video models against Gemma-2 9B-IT on the VaTeX dataset below. We test video models in three different settings. For image models, we consider two variants
In the original PRH paper, the authors postulate the following claim:
Different models will converge to the same representation when the input signals are sufficiently high information and the models are sufficiently high capacity. - Huh et. al., 2024.
Our results above reinforce that the previously observed low alignment was a result of the input signals being too impoverished, and that these models were sufficiently high capacity to begin with!
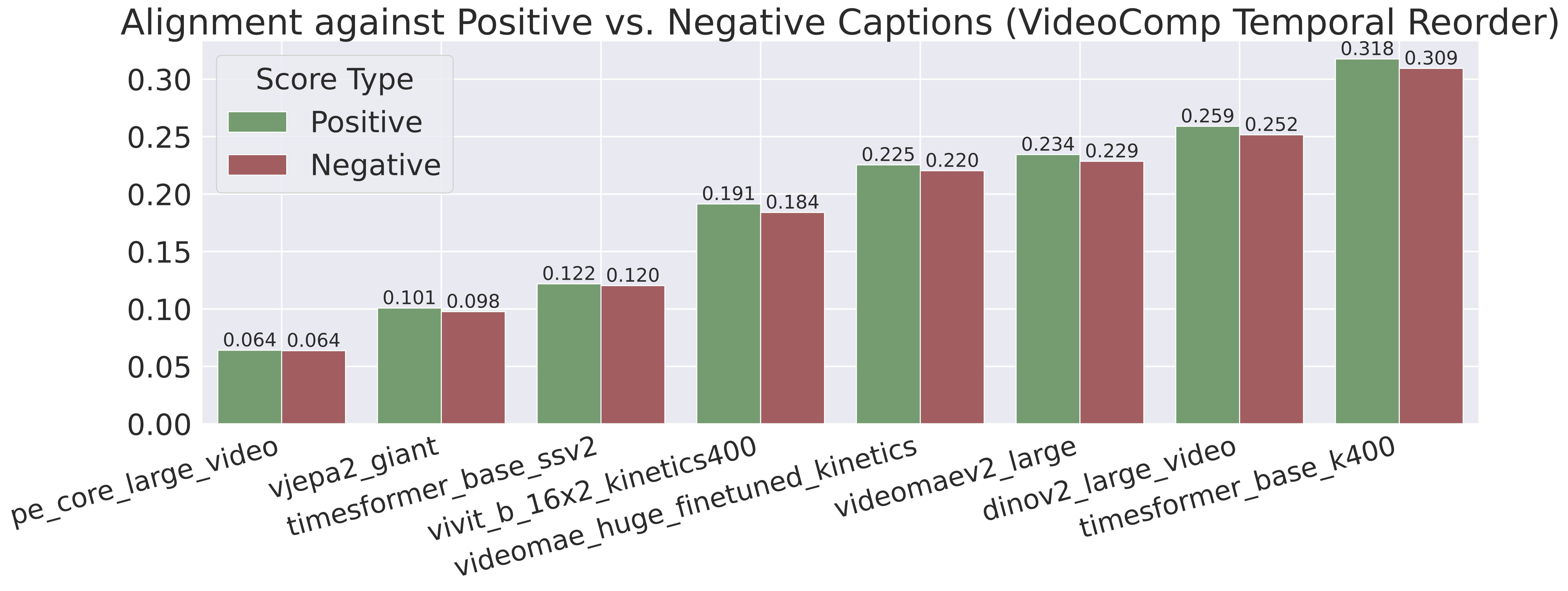
Seeing as we have dynamic inputs now, we can evaluate how dynamic our representations are. We evaluate this on two datasets: the synthetic Test of Time and the challenging, long-form VideoComp. On this second dataset, when we compute alignment against positive captions vs. temporally reordered negatives in text space, it drops slightly but not by much. This shows that there is still room for greater temporal understanding in our embeddings.

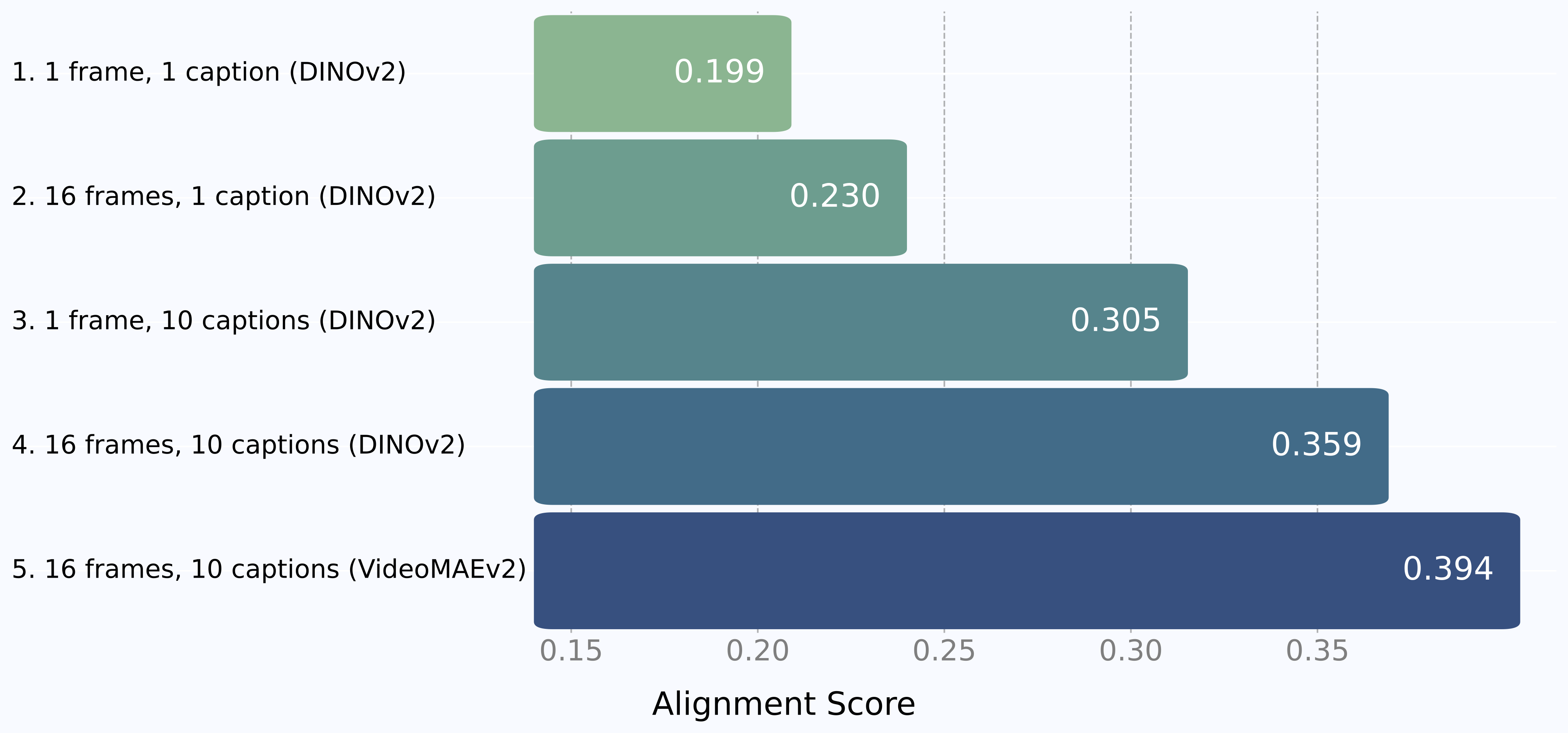
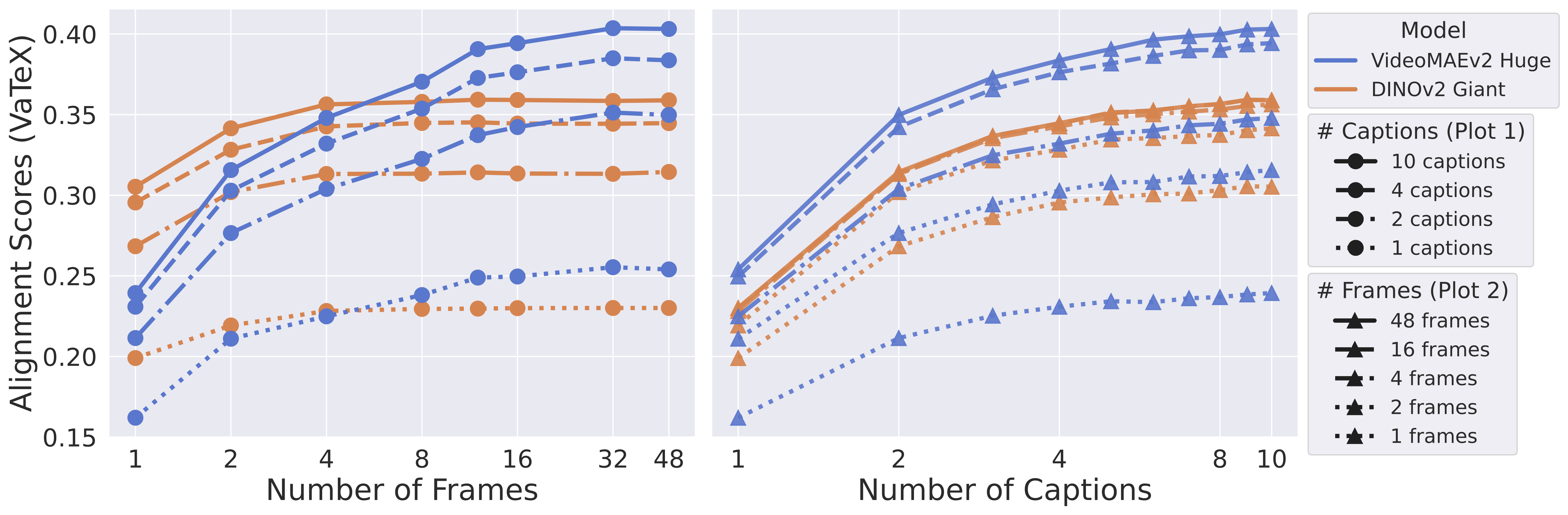
We find that video-text alignment can improve dramatically depending on the amount of data provided at test time.
As shown below, increasing the number of frames sampled from the video consistently improves alignment, as does increasing the number of captions. This makes sense: the more dynamic our inputs, the less we are approximating the true underlying reality. Scaling frames benefits video models like VideoMAEv2 more than image models like DINOv2.
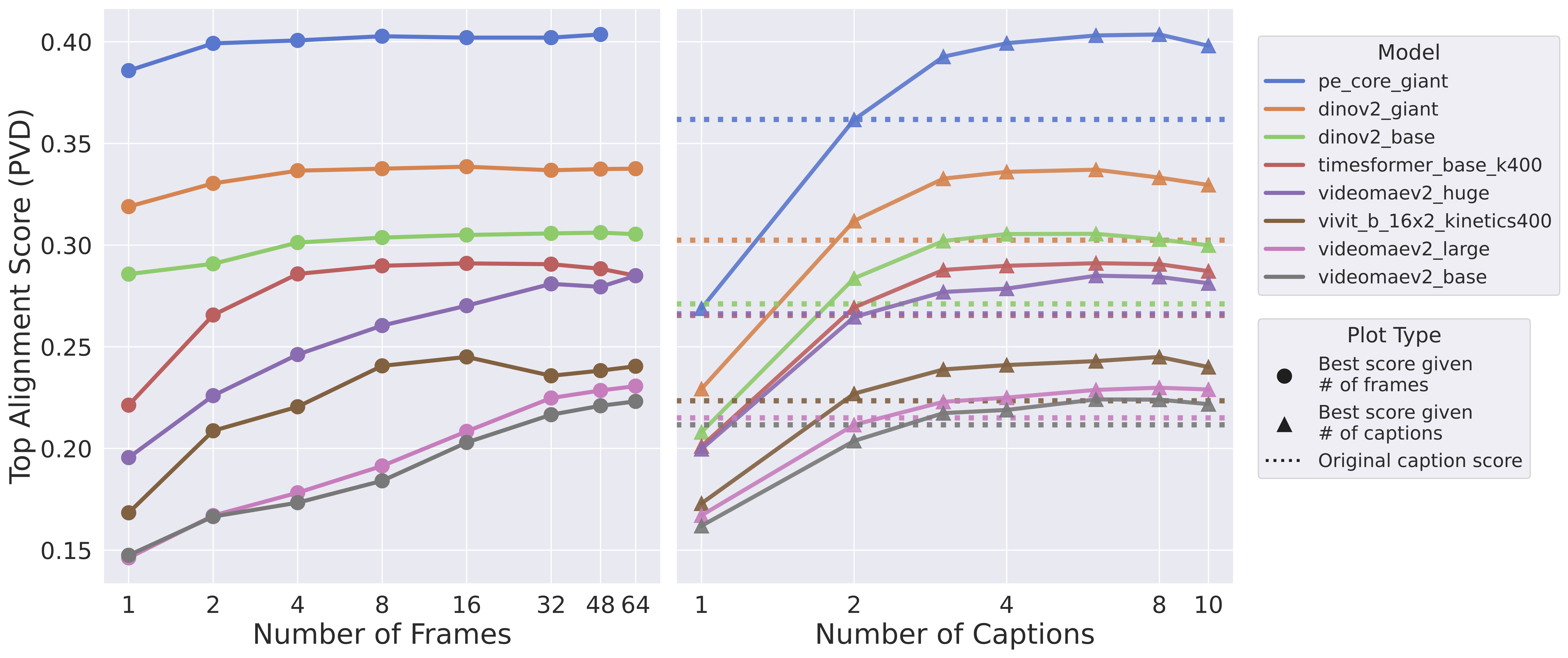
We found that even artificially synthesized caption descriptions from a single long video caption using an LLM can obtain alignment that is higher than that of the source caption. Namely, we find that our test time scaling approach improves alignment on the PVD dataset, which does not naturally come with multiple diverse captions, across a wide variety of models.
We can quantify this dependence using neural scaling laws similar to the ones proposed in the Chinchilla paper [6]. We found that a saturation-based model fits our observations remarkably well:
$$ \text{score}(\mathbf{n}_f, \mathbf{n}_c) = S_{\infty} - (C_f \mathbf{n}_f^{-\alpha} + C_c \mathbf{n}_c^{-\beta}) $$
Here, $\mathbf{n}_f$ and $\mathbf{n}_c$ are the number of frames and captions. The formula suggests that alignment approaches a maximum, "infinite data" score ($S_{\infty}$) as we add more data. The score is penalized by two terms that decay with the number of frames ($C_f \mathbf{n}_f^{-\alpha}$) and captions ($C_c \mathbf{n}_c^{-\beta}$). This model fits our empirical data with high fidelity (e.g., $R^2 > 0.97$ for VideoMAEv2), demonstrating that the benefit of additional test-time data is predictable.
$$ \text{VideoMAEv2}_{\text{score}}(\mathbf{n}_f,\mathbf{n}_c) = 0.41 - (0.15\mathbf{n}_f^{-0.75} + 0.13\mathbf{n}_c^{-1.30}) $$
$$ \text{DINOv2}_{\text{score}}(\mathbf{n}_f,\mathbf{n}_c) = 0.37 - (0.05\mathbf{n}_f^{-1.76} + 0.13\mathbf{n}_c^{-1.40}) $$
These fitted parameters provide insight into each model's unique behaviors. Notably, the frame exponent ($\alpha$) for DINOv2 is over double that of VideoMAEv2, while the caption coefficients and exponents ($C_c, \beta$) remain comparable, highlighting the video model's stronger ability to leverage temporal information from additional frames to improve alignment.
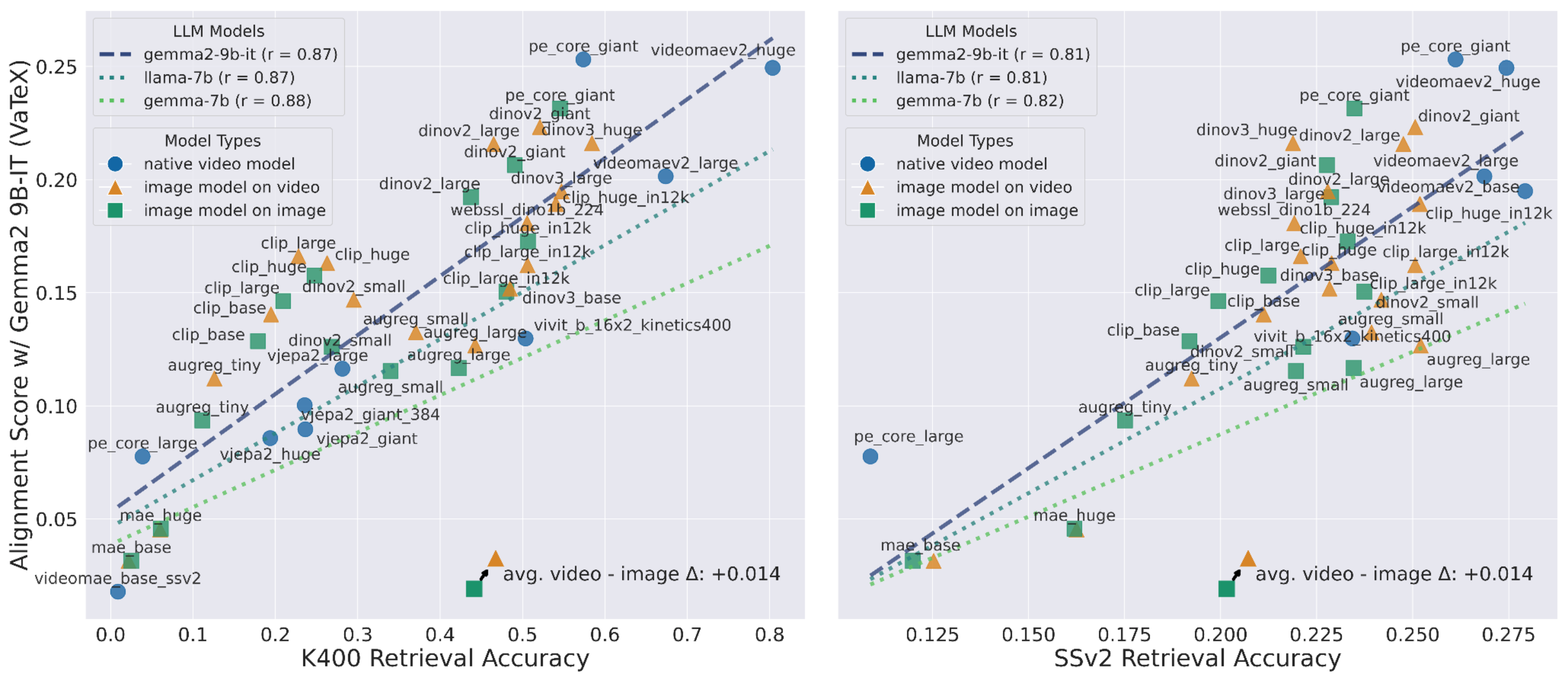
If this emergent alignment is meaningful, it should correlate with how well a video model performs on other video tasks. We tested this by comparing the alignment scores of various self-supervised video models (trained without text) to their performance on a range of downstream tasks, from semantic to low-level geometric tasks.
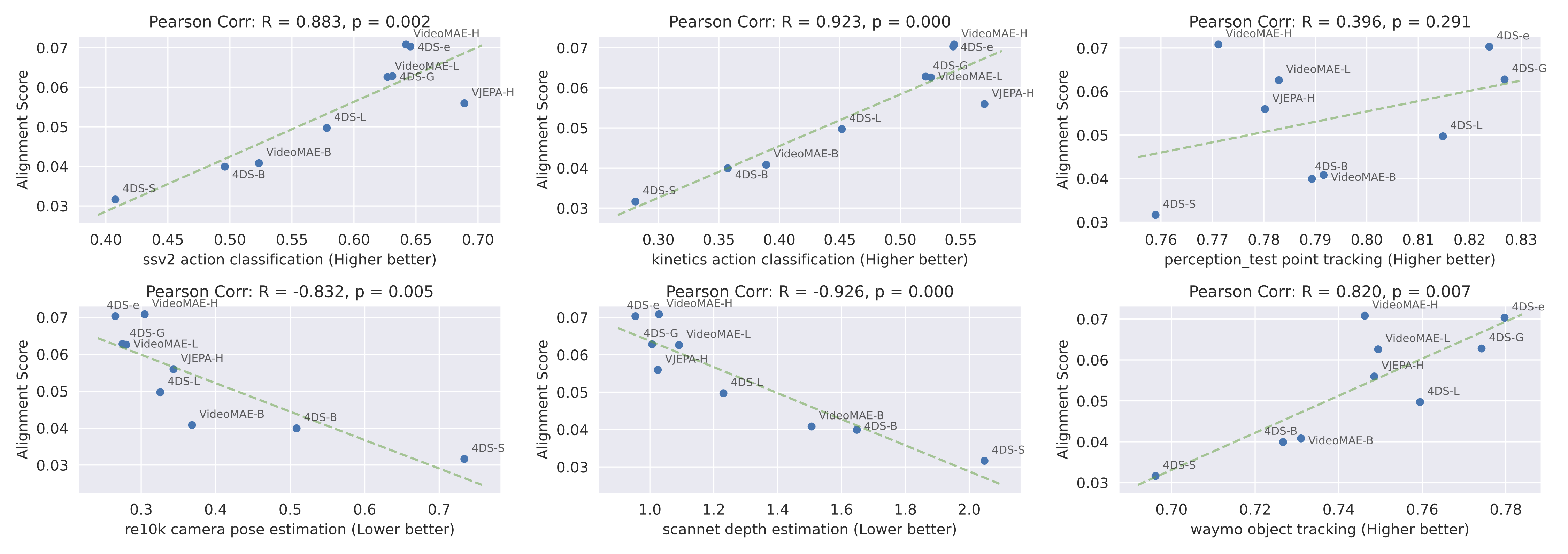
As shown above, we found a strong positive correlation. Models that align better with text also tend to perform better on semantic tasks like action classification (on datasets like Kinetics and SSv2) and, surprisingly, even on non-semantic, geometric tasks like depth estimation, camera pose estimation, and object tracking. Point tracking remains an outlier, pointing to more room for video models to improve in.
This suggests that video-text alignment can serve as a powerful, zero-shot indicator of a video model's general capabilities. Evaluating large video models can be expensive, often requiring extensive fine-tuning on multiple benchmarks. Platonic alignment provides a cheap and fast alternative by simply comparing a video model's representations with a standard text model on a small held out set. We can get a strong signal about its potential performance on a wide array of tasks, saving significant time and computational resources.
In this work, we extend the Platonic Representation Hypothesis to the temporal domain, demonstrating that video-text alignment scores can double simply by using more video frames and diverse captions at test time—without any retraining. We quantify this with a highly accurate saturation-based scaling law, confirming that native video models are better equipped to leverage temporal information than static encoders.
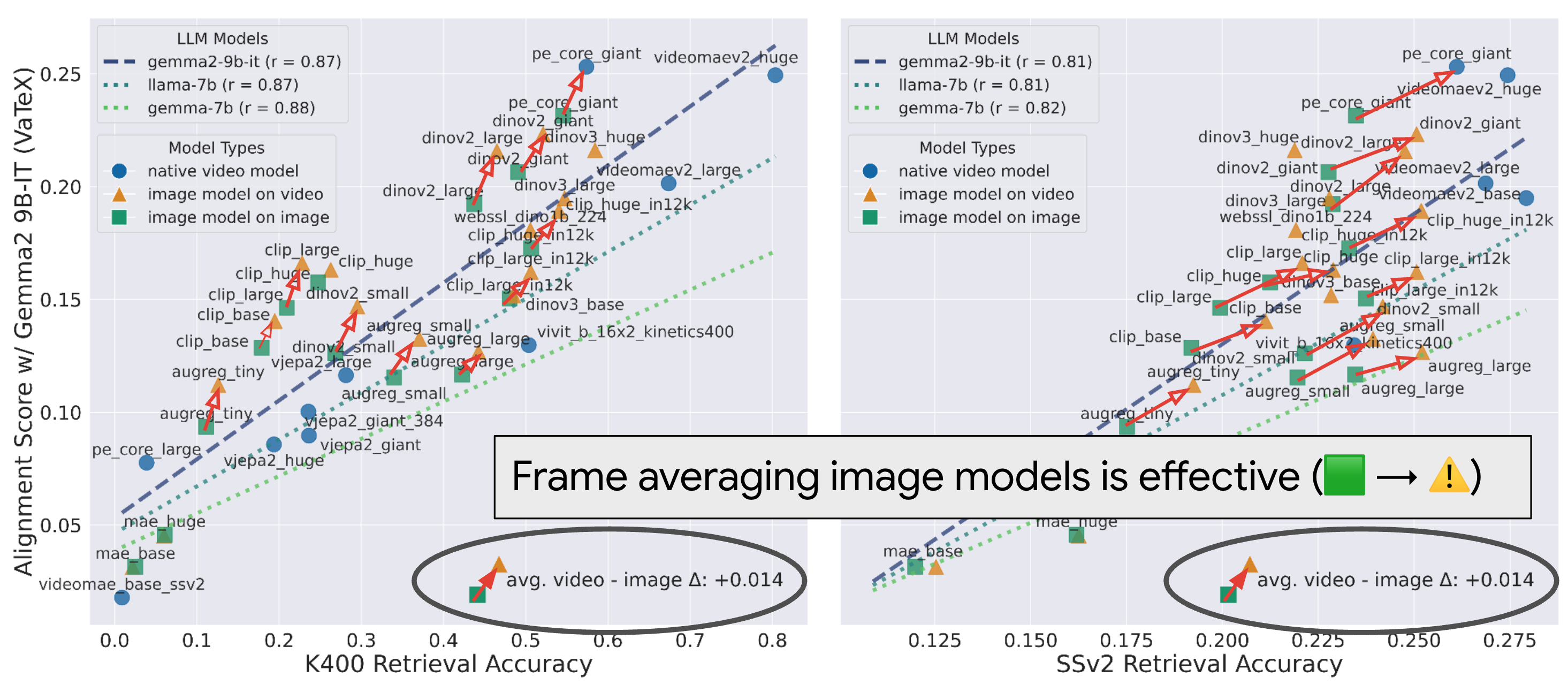
Our analysis reveals that this alignment score is a powerful zero-shot indicator of a model's downstream performance on both semantic and geometric tasks. However, it also highlights the limitations of current video models, some of which are still outperformed by simpler frame-averaging approaches. As video models continue to evolve, particularly generative ones, an open question remains: how can we best harness their latent representations for a deeper understanding of our dynamic world?
@misc{zhu2025dynamic,
title={Dynamic Reflections: Probing Video Representations with Text Alignment},
author={Tyler Zhu and Tengda Han and Leonidas Guibas and Viorica Pătrăucean and Maks Ovsjanikov},
journal={arXiv preprint arXiv:2511.02767},
year={2025},
}